Statistik

Beim Spiel mit einem fairen Würfel ist bekannt, dass jede der Seiten mit Wahrscheinlichkeit 1/6 oben zu liegen kommt. In praktischen Anwendungen ist es aber eher selten der Fall, dass bei einem Zufallsexperiment die exakten Wahrscheinlichkeiten aller Ereignisse wie hier aus physikalischen oder sonstigen Gegebenheiten direkt ablesbar ist.
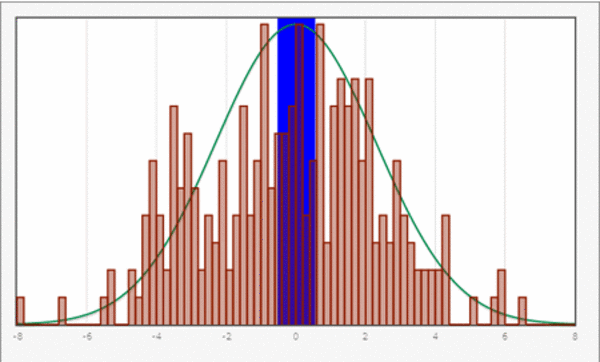
In diesen Fällen kommt die Statistik ins Spiel. Ihre Grundidee ist, das Experiment, für das eine stochastische Beschreibung gesucht ist, immer wieder durchzuführen. Bei hinreichend vielen Wiederholungen besteht die Hoffnung, dass das Ergebnis dieser Stichprobe repräsentativ für den Ausgang des Experimentes ist, und Rückschlüsse von der Stichprobe auf die Verteilung eines beobachteten Merkmals möglich sind.
In der deskriptiven Statistik werden konkrete Stichproben anhand von Kennwerten beschrieben. Dazu gehören vor allem Lagemaße wie der Median oder der Mittelwert sowie Streuungsmaße wie die empirische Standardabweichung. Die Anzahl der durchgeführten Experimente heißt dabei Stichprobenumfang.
Mit den Kennwerten aus der Stichprobe können tatsächliche Kenngrößen eines Merkmals geschätzt werden. So garantiert das starke Gesetz der großen Zahlen, dass die relative Häufigkeit für ein Ereignis in einer Stichprobe für immer größeren Stichprobenumfang gegen die Wahrscheinlichkeit dieses Ereignisses konvergiert, etwa strebt die Anzahl der geworfenen Fünfen beim Werfen eines fairen Würfels gegen 1/6. Ebenso konvergiert der empirische Mittelwert in einer Stichprobe gegen den tatsächlichen Erwartungswert des Merkmals, beim Würfeln etwa strebt der Mittelwert gegen 3,5. Ist für ein Merkmal nur die Verteilungsfamilie bekannt, so können auf diese Weise auch die unbekannten Parameter geschätzt werden.
Allerdings ist klar, dass beim Würfeln auch nach sehr vielen Würfen die relative Häufigkeit für die Zahl Fünf zwar in der Nähe von 1/6, und der Mittelwert in der Nähe von 3,5 ist, aber exakte Gleichheit kann nicht garantiert werden. Umgekehrt bedeutet dies, dass Kenngrößen oder Parameter der Verteilung eines Merkmals mithilfe von statistischen Methoden niemals exakt ermittelt werden können, beim Schätzen muss immer ein gewisses Maß an Ungenauigkeit einkalkuliert werden.
Die wesentliche Aufgabe der induktiven Statistik ist es, diese Ungenauigkeit zu quantifizieren. Die gängigen Verfahren hierzu sind das Durchführen statistischer Tests und das Berechnen von Konfidenzintervallen.